Our solution takes you from single cell or single-nuclei suspension through library prep and sequencing and delivers immediate results via our analysis software, Trailmaker.
Our solution takes you from single cell or single-nuclei suspension through library prep and sequencing and delivers immediate results via our analysis software, Trailmaker.
Large-Scale, Single Cell Datasets Available for Commercial Licensing
Accelerate your drug discovery programs and power the next generation of AI models with access to some of the largest and most comprehensive single cell datasets available for commercial use. All datasets are generated using Parse’s Evercode combinatorial barcoding technology, enabling unmatched scale and quality. The following datasets are available for commercial use following completion of a license agreement.
Access raw and processed data, complete metadata, and experimental details to fast-track your internal research programs. This supplements your existing internal pipelines and shortens discovery cycles.
What’s Included with a Licensed Dataset
Each dataset license is fully configurable to meet the requirements of your organization. Parse provides a range of deliverables, including raw FASTQ files, processed gene count matrices, metadata, and detailed experimental documentation, and will tailor access to match your analytical pipelines and research objectives. Our team collaborates with you to determine the scope, format, and level of support that advance your research objectives.
Overview of Available Datasets for Commercial Licensing
Below is the current catalog of datasets available for licensing. New large-scale drug perturbation datasets are in progress and will be released soon.
1. 10 million human PBMC screen with 90 cytokine treatments
PBMCs from 12 human donors (6 male; 6 female) were subjected to 90 cytokine treatments plus PBS control for 24 hours (Figure 1, left).
Fixed samples were processed in the GigaLab using a Hamilton liquid handler. Libraries were sequenced using the Ultima Genomics sequencing platform and achieved ~31,000 mean reads per cell.
9,697,974 cells across 18 immune cell types were identified, including rare populations (Figure 1, right).
Full details of experimental setup and preliminary findings are on our website.
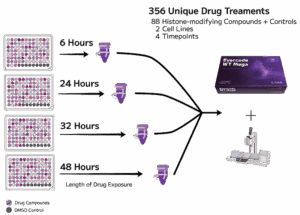
2. High-throughput profiling of a cancer cell line drug screen
Two cancer cell lines: A549 (lung carcinoma) and THP-1 (acute monocytic leukemia) were subjected to 88 histone-modifying drug treatments plus DMSO controls at 2.5 µM for 6, 24, 32, or 48 hours (Figure 2).
Cells were fixed using the Low Input Fixation workflow, processed through the Evercode WT Mega 384 kit automated using Integra Assist Plus pipetting robot.
Approximately 20,000 cells per treatment and ~10,000 reads per cell.
Full details of experimental setup are on our website; data can be explored in Trailmaker.
Figure 2: Experimental design for the high-throughput cancer cell line drug screen.
3. An anti-diabetic 88-compound, four-timepoint single cell drug screen
HEK293 and NIH-3T3 cells received 10 µM treatment for 1, 3, 6, or 24 hours.
The panel of 88 small molecule anti-diabetic drugs covered diverse mechanisms of action, including insulin sensitizers, sulfonylureas, and DPP-4 inhibitors, plus DMSO controls (Figure 3).
~20,000 cells per well were fixed using the Low Input Fixation workflow and processed through the Evercode WT Mega 384 kit.
Full details of experimental setup are on our website; data can be explored in Trailmaker.
1
2
3
4
5
6
7
8
9
10
11
12
A
GW9508
Zebularine
Acarbose
CHIR-99021 (CT99021)
Alogliptin Benzoate
Bardoxolone methyl
Bilobalide
Curcumin
SRT2104 (GSK2245840)
Teneligliptin hydrobromide
Trelagliptin
DMSO
B
Troglitazone
Glimepiride
Linagliptin (BI-1356)
Sitagliptin phosphate monohydrate
Vildagliptin (LAF-237)
Alogliptin (SYR-322)
Rucaparib (AG-014699; PF-01367338)
SRT1720 HCl
Resveratrol
Rosiglitazone maleate
GSK3787
DMSO
C
Rosiglitazone
GW0742
GW501516
Rosiglitazone HCl
Roflumilast
Pioglitazone HCl
MK-8245
PF-04620110
Piperlongumine
Streptozocin
Empagliflozin (BI 10773)
DMSO
D
Repaglinide
Dapagliflozin
R406 (free base)
R788 disodium
Canagliflozin
TAK-875
CHIR-99021 (CT99021) HCl
Glipizide
GSK1292263
R406
Fingolimod (FTY720)
DMSO
E
Saxagliptin
Alvelestat
AZD7545
Glibenclamide
Phenformin HCl
RVX-208
Bethanechol chloride
Bosentan
Chlorpropamide
Methyldopa
Voglibose
DMSO
F
AdipoRon
Fenofibrate
Gemfibrozil
Inulin
Metformin HCl
Sodium Salicylate
Miglitol
Pioglitazone
LY2608204
Tolbutamide
Gliclazide
DMSO
G
Gliquidone
Nateglinide
Ramipril
Valsartan
WAY-100635 maleate salt
Fostamatinib (R788)
Lisinopril dihydrate
Hydroxychloroquine sulfate
WS6
Obeticholic acid
MK3102
DMSO
H
Triacetyl Resveratrol
Diflunisal
Bromocriptine mesylate
(R)-(+)-Etomoxir sodium salt
Astaxanthin
Tauroursodeoxycholic acid
L-(-)-Fucose
Maslinic acid
Morin
L-Leucine
(2S,3S)-2-Amino-3-methylpentanoic acid
DMSO
Figure 3: Plate layout of the 88-compound anti-diabetic drug screen.
4. 5 million mouse single nuclei atlas from 7 tissues
Tissues collected for the atlas included the liver, eye, heart, kidney, colon, quadriceps muscle, and brain, harvested from one male and one female mouse.
Samples were processed using the Evercode WT Penta kit, and 32 sublibraries sequenced using a NovaSeq X at a sequencing depth of 10,000 reads per cell.
5 million nuclei were mapped to 211 distinct cell types, including rare and complex subtypes.
Full details of experimental setup are on our website; data can be explored in Trailmaker.
Figure 4: UMAP of the 5 million mouse single nuclei atlas.
Dataset Comparison
Dataset
Number of Cells / Nuclei
Number of Samples
Number of Reads per Cell
Treatments / Condition
Timepoints
Species
Ideal Applications
10M PBMC Cytokine Screen
~9.7M
1092
~31,000
90 cytokines
24h
Human
Immunomodulatory drug discovery Donor variability and stratification studies Training ML models for immune response prediction
Comparative MoA analysis across compound classes Identifying off-target or compensatory transcriptional effects Training predictive drug response models