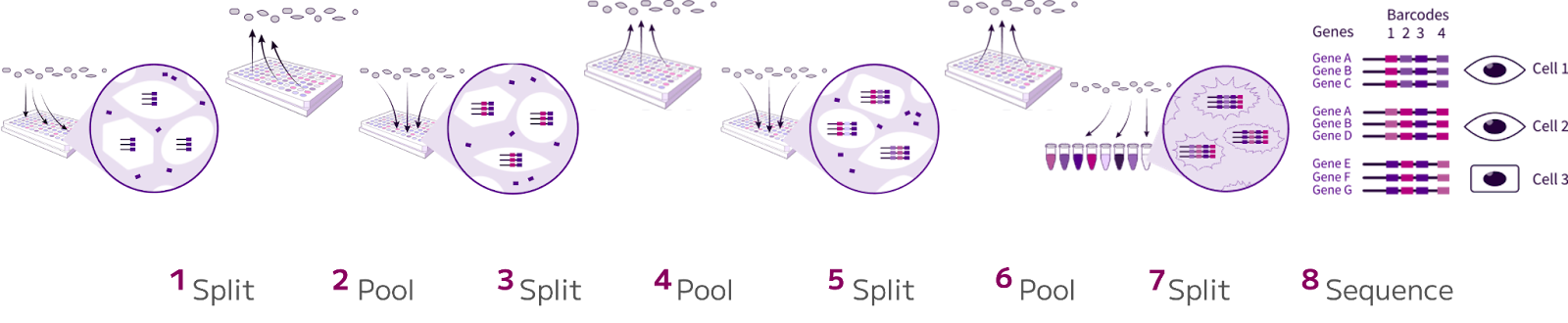
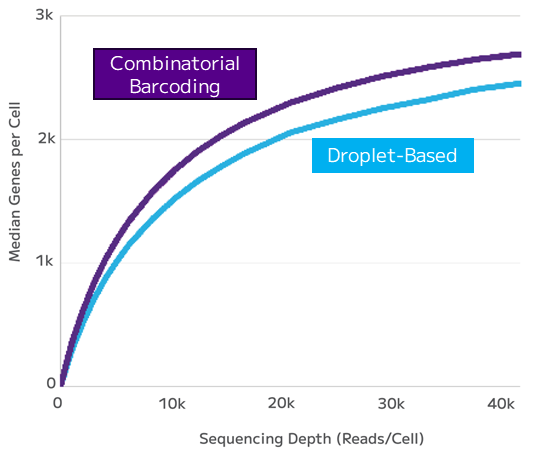
Despite the advantages of being relatively high-throughput and capable of capturing a wide range of cell types, droplet-based technologies face challenges when applied to immunology research.
Inefficient Capture of Certain Immune Cell Types
Inefficient capture means that the cell’s RNA was not successfully captured and sequenced. There are a few reasons why this may happen.
Cells may be prone to lysis. Granulocytes (neutrophils, eosinophils, basophils) have a fragile nature and high susceptibility to lysis during droplet encapsulation, therefore they may be difficult to capture. Due to the presence of RNAses, these cells have high RNA degradation rates that further contribute to poor transcript recovery.
Some cell subsets are rare and may be masked by more abundant cell populations. For instance, dendritic cells are a low-abundance subset making up for 1-2% of the peripheral blood mononuclear cells. To capture even a small number of these cells using droplet-based methods, researchers must input a very large number of total cells, which increases cost and data volume.
Additionally, they are prone to clumping due to their size, surface adhesion molecules, and tendency to form cell–cell contacts. This leads to inefficient droplet formation or exclusion, or even clogging the chip, causing them to be underrepresented or entirely missed.
Low RNA content cells add another challenge. Immune subsets such as some tissue resident neutrophils with low RNA content can be challenging to detect due to their reduced RNA levels compared to other immune cells. In droplet-based workflows, these low-RNA cells may fail to generate sufficient signal for library preparation, leading to poor-quality barcodes, sparse gene counts, or complete dropout from the dataset. As a result, these biologically important but transcriptionally quiet cells can be underrepresented or misclassified in downstream analyses.
Cell Size and Droplet Compatibility
A droplet has on average 50-60 𝛍M in diameter. Large cells such as activated macrophages or monocytes may exceed this size range, presenting significant challenges.
They may not properly fit within the droplet or the microfluidic channels leading to low capture rate. Additionally, these cells are more prone to clog the microfluidic device leading to disruption of the workflow. The inability to effectively capture these large cells limits the applicability of droplet-based protocols in comprehensive immunological studies that analyze a heterogeneous population including both small and large cells.
Another size-related issue that can clog microfluidic systems is cell clumping. Certain T cell subsets, monocytes, or the DNA released from lysed or dead cells can promote aggregation and clumping. This aggregation can lead to incorrect barcoding, loss of single cell resolution due to higher doublet/multiplet percentage, and, in severe cases, clogging of the microfluidic channels.
Ambient RNA and Red Blood Cells contamination
Extracellular RNA molecules—freely floating RNA not associated with any intact cell—are RNA originating from lysed or dead cells, broken during sample preparation, processing, or handling. They can also be present due to secreted RNA or cell debris. Higher ambient RNA contamination is a common problem in droplet-based technologies.
Blood samples are prone to high red blood cells (RBC) retention. When RBCs lyse they release free-floating hemoglobin’s RNA that can be encapsulated into a droplet and sequenced with the intracellular RNA, leading to cell type misidentification and erroneous gene profiling conclusions. Moreover, as ambient RNA is sequenced as well, a portion of the reads will be wasted on non-useful information the user is still paying for. (Figure 2).
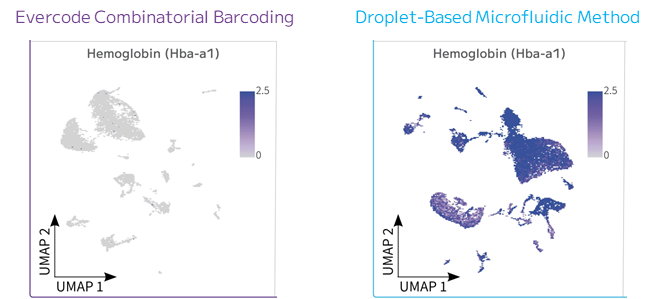
Figure 2: Clustering and Hemoglobin Expression Comparison. Expression of hemoglobin alpha is shown for both Evercode combinatorial barcoding and droplet-based technologies.